Azure Databricks DBFS and Interactive Ways with Local Image and Azure ADLS
In today’s technology industry, Databricks has undoubtedly become a unicorn company in big data distributed processing, data analysis, data visualization, and machine learning. In the current era of cloud computing, the three major cloud service providers, Microsoft, Amazon, and Google, have all incorporated Databricks into their cloud computing platforms. This shows Databricks’ unique contribution to data cloud computing and its pivotal role in the development of enterprise-level data products.
With the decreasing cost of cloud storage and the improvement in network speeds, more and more enterprises are choosing to store all their data in a central repository rather than separately storing different types of data. This trend towards centralization helps companies better understand their business operations through real-time business intelligence and predictive analytics. At the same time, the explosive growth of data has made it impractical for companies to maintain multiple large data stores, leading to the merging of data lakes and data warehouses into a single platform. Based on the Lakehouse technology architecture, Databricks provides platform-level services that integrate data storage, processing, visualization, and machine learning into a unified environment. As a result, more and more enterprises are choosing Databricks as their primary cloud data service platform, and developers also prefer Databricks Notebook as a unified development and presentation environment.
Recently, in the process of coordinating with the engineering team of our business product supplier, we needed a large number of scripts and images for development and presentation. It is clearly not a good practice to frequently switch between the development environment and image applications. Therefore, we need a method to integrate images into Databricks notebooks and combine them with its dashboard functionality to present data, charts, and images together. This can greatly improve the user experience.
Insert images in Databricks notebook
First of all, we need to upload the images to Databricks DBFS file system and it is very similar to the upload data file through the Add data GUI, as shown in the following, in the catalog homepage of your workspace, click Add data button on the up right corner (position might different depends on version), then click DBFS tile. Usually, we store file in FileStore directory which is prebuilt for customer data/file, in our case, we upload images file in /FileStore/tables/images/ directory.


Because Databrick notebook supports markdown so that you might think the only thing for this task is copy the path which is generated automatically when uploading completed like /FileStore/, it may seem to be right, but that is tricky one, we need to replace FileStore with files otherwise, it won’t show anything in the cell, another thing we need to pay attention is the path should be directly written inside the parenthesis without quote, as shown down below


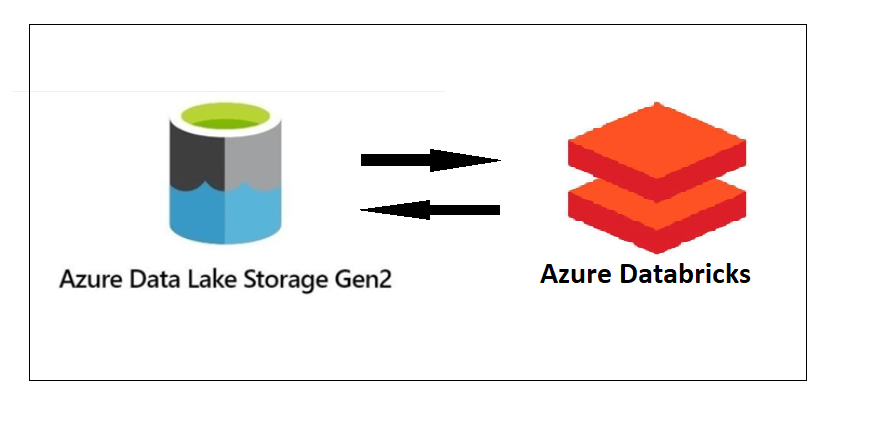
Access Azure Datalake Gen2 Storage with Azure Databricks
Another use case is reading a huge amount of data from an external data source. Although Databricks provides GUI data upload functionality, it is limited to small test data sets. In actual production scenarios, data is mostly read from Azure Data Lake Storage (ADLS) and then written to Delta Lake. With the unified platform advantage of Azure Databricks and Azure Data Lake Storage (ADLS), we can directly read data from ADLS into Databricks and also mount the ADLS container directly to the Databricks DBFS file system.
Write ADLS Data to Delta Lake
There are two ways to ADLS storage account container
- Access Key
- Shared Access Signatures (SAS)
SAS gives more control on the access, Databricks recommends using a service principal or a SAS to connect ADLS instead of access key, but for simplify our demo, we will discuss the way by using access keys, it provides full access to the configuration of a storage account, as well as the data.
Step1, we need to login Azure portal and ADLS account to get the account name and access key, then define the data file path and the file type, next set Spark properties to configure a Azure credentials to access Azure storage. The credentials can be scoped to either a cluster or a notebook.
1 | storage_account_name = "adlstest1" |
1 | file_location = "abfss://testContainer1@adlstest1.dfs.core.windows.net/test_file.csv" |

File path parameter is consist of “abfss://“ + {container name}@{storage account name} + “.dfs.core.windows.net/“ + {file name}. Here is a tricky thing of the path, the path is only valid when data file is in container (files can’t be put into subfolder in the container otherwise the path wouldn’t work) so that Databricks can’t read file from below path
“file_location = “abfss://testContainer1@adlstest1.dfs.core.windows.net/data_file/test_file.csv”
1 | # configure Azure credentials |
Step 2, we have specified out file metadata, we can create a Dataframe. Notice that we use an option to specify that we want to infer the schema from the file. We can also explicitly set this to a particular schema if we have one already
1 | df = spark.read.format(file_type).option("header", "true").option("inferSchema", "true").load(file_location) |

We can also reference a video in YouTube on this technology
Mount ADLS Container to Databricks DBFS
There is a great article in Medium to introduce that technology with name Mount ADLS on Databricks, click the article name to redirect to the article site.