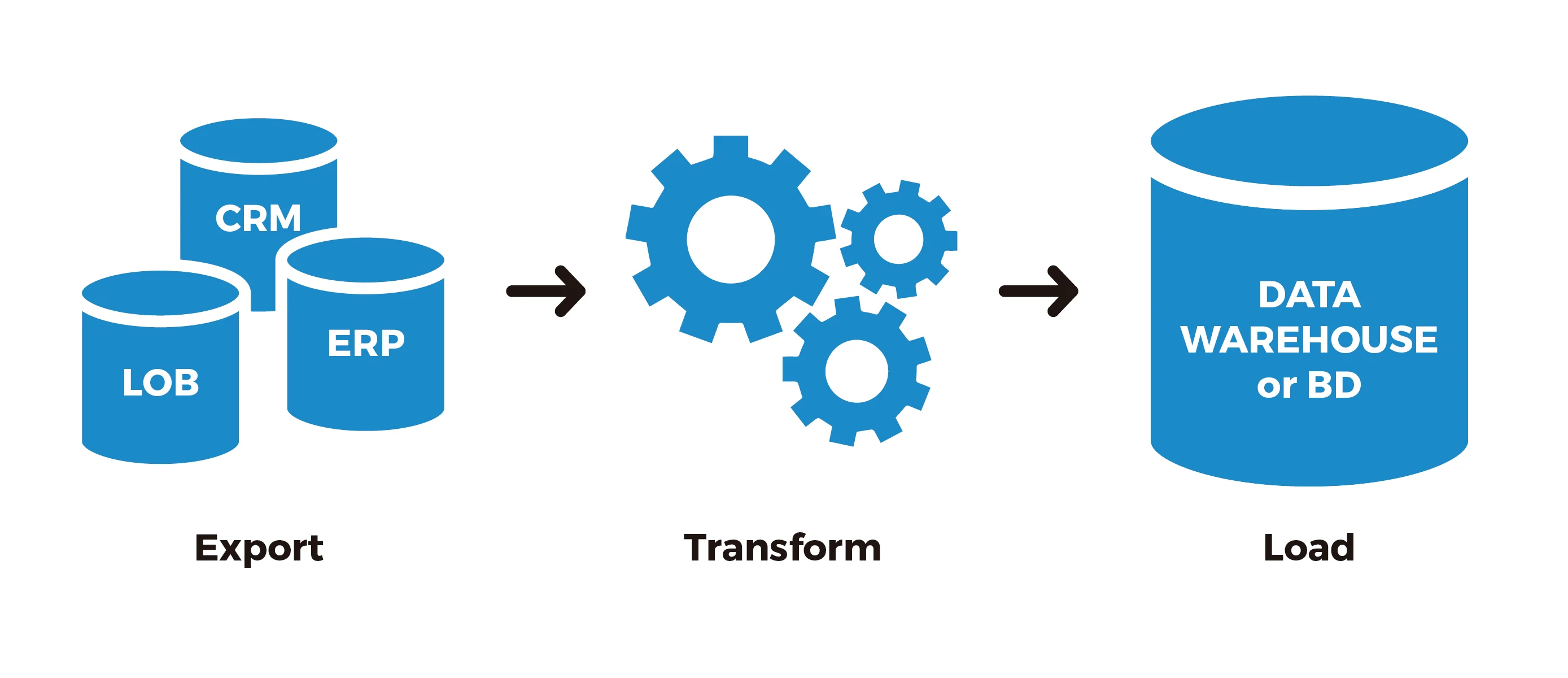
This post is part 2, we are focusing on design and create data process to extract, transform and load (ETL) big amount data into partitioned tables to be able to integrate to SSIS package then operate ETL process by scheduled job automatically.
In this case, we suppose transaction data with 100 columns and 100 million records need to be loaded into data warehouse from staging table. Technically, we can do partition switching from staging table (non partitioned table) to data warehouse table (partitioned table), but under the business reality, we can’t just simply do it like that, because
- Source table and target table usually are in different database, it’s not able to switch data directly because of violating same file group condition by partition switching basic in part 1.
- Staging table would be empty after partition switching, but the most of data transformations are applied to staging table then load final results into target table in data warehouse, so in business point of view, we can’t do partition switching from staging to target neither because big impact for entire daily, weekly or monthly data process.
There might be another question: why don’t we bulk load data from source to target or what benefits do we get from partition switching? Technically, yes, we can do bulk insert, however, for such big volume of data movement, the lead time is going to be hours (2-3 hours), if the process ran on business hours, it would cause big impact and it’s hard to tolerant by business users for critical data like transaction so from efficiency and performance perspective, we have to leverage partition switching to deliver transaction data in short period of time without interrupt BI reports, dashboard refresh and business analysis.
What is the main idea for production operation?
In order to promise transaction data is always available, we need to create a middle table to hold transaction data as source table for partition switching, we call that middle table as switch table. To satisfy all the requirements for partition switching, the switch table has to be created in as the same file group as target transaction table, identical columns, indexes, use the same partition column. We do the bulk insert from staging table to switch table then partition switch to target transaction table in data warehouse, as part 1 mentioned, this step will finish in flash as long as there is no blocking. At last, we drop switch table so the entire data process completes. Now let’s dig litter deeper on details for each steps.